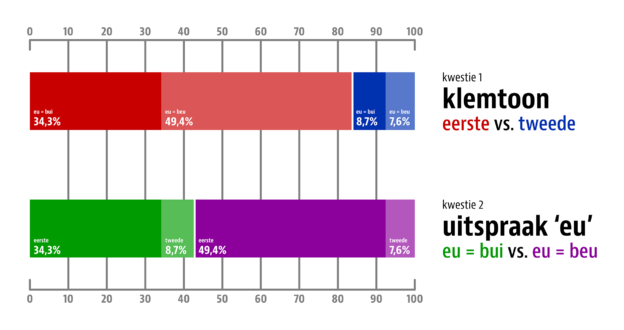
Wer Deutsch spricht, stößt schnell auf ein Phänomen, das als ›Wechselflexion‹ bezeichnet wird. Schon im ersten Satz dieses Texts sind zwei Beispiele enthalten, nämlich spricht und stößt. In beiden Fällen weist der Infinitiv des Verbs, sprechen bzw. stoßen, einen anderen Wurzelvokal auf als die zweite und dritte Person Singular im Präsens (sprichst und spricht bzw. stößt für beide Personen). Agné (2016) definiert Wechselflexion als »Vokalwechsel im Präsensparadigma starker Verben«.
Das Phänomen ist aus verschiedenen Gründen interessant: Zum einen kommt es in einigen Varietäten vor und fehlt in anderen eng verwandten. Im deutschen Sprachraum findet man es nicht nur in der Standardsprache, sondern auch in westmitteldeutschen Regionalsprachen (mehr dazu bei Agné 2016). Im Standardniederländischen ist es hingegen nicht (mehr) vorhanden; dafür kommt es auch in den Niederlanden regional vor: Ich habe vor einigen Jahren über die Systematik des Vokalwechsels im Gronings geschrieben (mehr dazu in Schoonhoven/Bergmann 2015). Andere niederdeutsche/niedersächsische Varietäten auf der niederländischen oder der deutschen Seite der Grenze zeigen den Vokalwechsel ebenso wie das Westfriesische. Auch in südlichen Regionalsprachen auf dem Gebiet der Niederlande, zum Beispiel der Varietät von Maastricht, ist der Vokalwechsel belegt. Und auch im Luxemburgischen begegnet man diesem Phänomen. Außerhalb des Westgermanischen tritt Vokalwechsel im Färöischen auf. Zum anderen ist die Funktion, die der Vokalwechsel in den Varietäten erfüllt, in denen er vorkommt, recht unklar. Und zum Dritten ist der Vokalwechsel Gegenstand von Variation: Während im Deutschen bei weniger frequenten Verben Abbau zugunsten des Infinitivvokals zu beobachten ist (so lauten die Formen von flechten für viele nicht mehr flichtst, flicht, sondern flechtest, flechtet), hat das Luxemburgische Verben in das System einbezogen, die historisch nicht daran teilgenommen haben.

Dieser Blogpost will einen kleinen Beitrag zur Erfassung der Wechselflexion im Luxemburgischen und Deutschen leisten. Meines Wissens gibt es keine frei verfügbare Online-Übersicht, die spezifisch alle Verben des Standarddeutschen und des Luxemburgischen auflistet, die von Wechselflexion betroffen sind. Eine solche Übersicht stelle ich am Ende dieses Beitrags zur Verfügung – in der Hoffnung, dass sie Lernenden das Erlernen und Forschenden das Erforschen dieses Phänomens erleichtert.
Weiterlesen