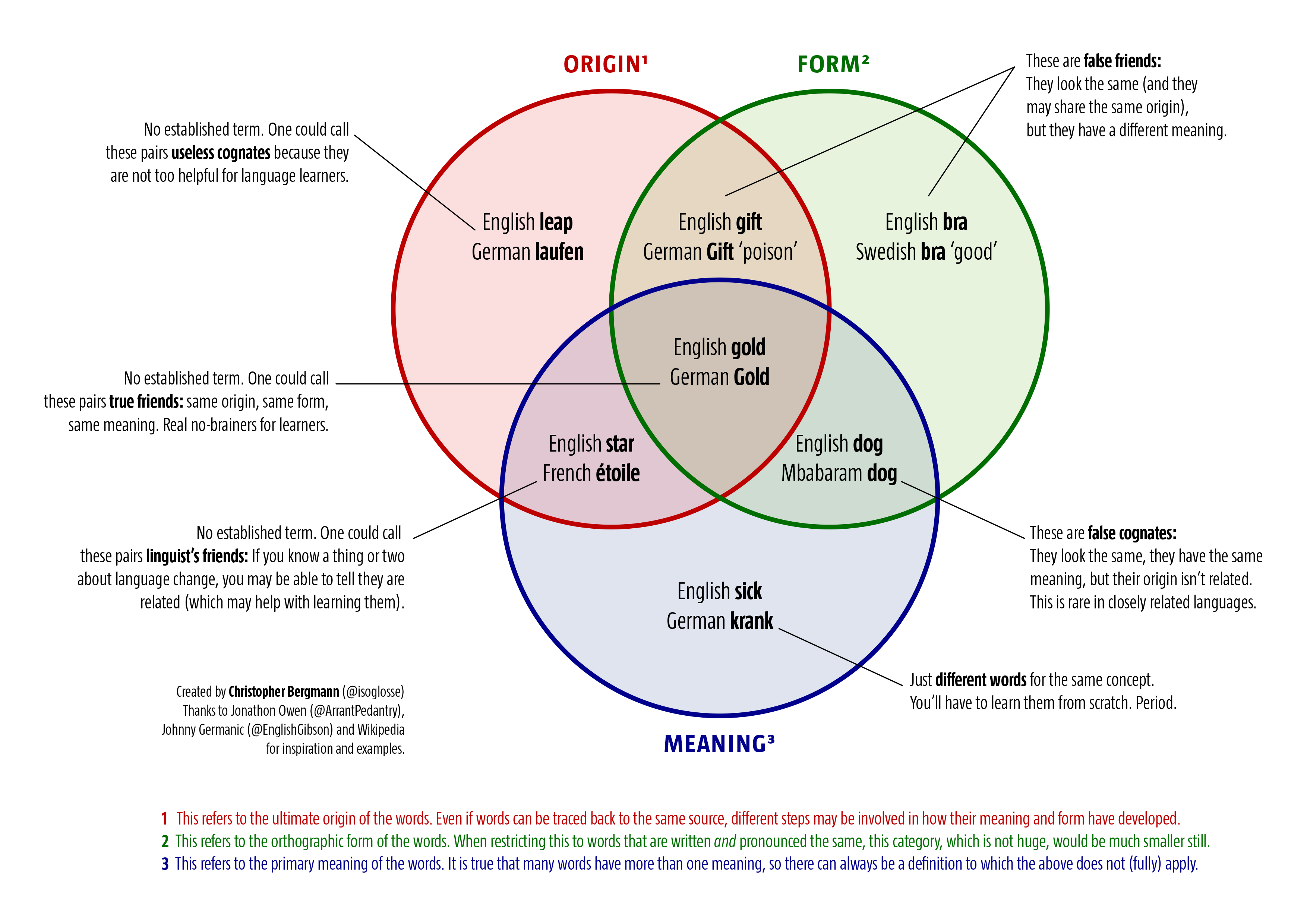
“Ach, Scheiße!” – that is what the cashier at the supermarket said to me today when he noticed that he had failed to scan one last item that I wanted to buy. It still lay on the conveyor belt while the receipt was being printed. What he said led me to think about the word ‘Scheiße’, one of the most common swearwords in German (and even popular in English song lyrics). Whenever you feel like shouting ‘Shit!’ in English, a speaker of German might chime in and shout ‘Scheiße!’. In the literal sense, ‘Scheiße’ refers to faeces; it is used in that sense quite frequently. The noun and its corresponding verb, ‘scheißen’, are labelled as ‘coarse language’ in German dictionaries. ‘Scheiße(n)’ derives from the Proto-Indo-European root *skeh₂i-d- ‘cut, separate’, which is an extension of PIE *skeh₂i- ‘split, divide’. It is a cognate of English ‘(to) shit’. Cognates are words that, across or within languages, share the same etymology. In some cases, this is quite obvious: The German sentence ‘Das Gras ist grün’ only contains words with cognate equivalents in English that have retained a similar form and meaning, so English speakers won’t have a lot of trouble figuring out what the sentence means. Sometimes the connections are less evident: English ‘lock’ and German ‘Loch’ (meaning: ‘hole, opening’) seem to go back to the same Proto-Indo-European root, for instance. In any case, German ‘Scheiße’ and English ‘shit’ are clearly cognates and used similarly in present-day language. That’s the boring part.
The interesting part is what happened to this root and its derivations in the Dutch part of the West Germanic language area. The verb that corresponds to ‘scheißen’ and ‘to shit’ is ‘schijten’ /ˈsχɛɪ̯tən/. It has the same meaning as in the other two languages and can be used in the literal sense: ‘Zij heeft in haar broek gescheten’ (literally: ‘She has shit in her pants’, meaning: ‘She has shit her pants’). ‘Schijten’ is used much less widely than its German and English cognates. However, there are some fixed multi-word expressions in which it appears, such as ‘zeven kleuren (bagger) schijten’ (literally: ‘to shit seven colours [of mud]’, meaning: ‘to be[come] very frightened’). When words are mainly used in fixed expressions, this is an indication that they might have started to fall into obsolescence. The corresponding noun, ‘schijt’, is even one step further: Some hundreds of years ago, it still referred to faeces, or to liquid stool in particular, but the only meaning in contemporary language is ‘the state of having diarrhoea’. Unlike ‘Scheiße’ and ‘shit’, ‘schijt’ is not used as a swearword in Dutch. Rather, it is almost exclusively encountered in fixed expressions: figurative ones, such as ‘schijt hebben aan iets’ (literally: ‘to have shit on something’, meaning: ‘to not care about something’), and literal ones, such as ‘aan de schijt zijn’ (literally: ‘to be at the shit’, meaning: ‘to have diarrhoea’). What’s even more interesting: The most common Dutch word derived from the same source as ‘Scheiße’ and ‘shit’ is ‘scheet’ (which happens to be identical to the singular simple past form of ‘schijten’). But ‘scheet’ means—wait for it—‘fart’. So, the German and English words for solid excreta and the Dutch word for gaseous excreta are cognates.
What do you call faeces in colloquial Dutch? In fact, English and Dutch are to be greatly envied from a German perspective. A word from nursery language has spread to more general use in both languages, meaning that you can talk about shit without sounding vulgar or clinical. The words I am referring to are ‘poop’ and ‘poep’, the Dutch word being pronounced about the same as the English one. In English, ‘poop’ has a certain childish ring to it. Still, you can use it not only when talking to a toddler, but also in a newspaper headline. This is also the case with Dutch ‘poep’ (and the corresponding verb ‘poepen’), but it sounds even less childish than the English word. A Dutch newspaper recently ran an article that was titled ‘Omdat iedereen poept’ (‘Because everyone poops’). You’d be hard-pressed for a stylistically appropriate translation to German. Well, why don’t the Germans use the cognate equivalent of the Dutch and English words? Here’s the complication: There is an equivalent in German, namely ‘Pup(s)’, but it means—wait for it—‘fart’ (in a slightly childish, euphemistic register). All three words are onomatopoetic, that is, an attempt at a phonetic imitation of a real world sound. What is being imitated is, of course, the sound of flatulence. English ‘poop’ and Dutch ‘poep’ can refer to that as well, but the meaning ‘fart’ has all but died out in English. In Dutch, it is found in—you guessed it—fixed expressions, such as ‘iemand een poepje laten ruiken’ (literally: ‘to have someone smell a little fart’, meaning: ‘to put somebody in their place’). By contrast, the German word ‘Pup(s)’ means nothing but ‘fart’—just like ‘Furz’, the cognate of English ‘fart’, which is perceived to be somewhat more vulgar. So, the Dutch and English words for solid excreta and the German word for gaseous excreta are also cognates.
In consequence, this means that speakers of English and German with no knowledge of Dutch are likely to be led up the garden path when encountering ‘scheet’, just the way English and Dutch speakers with no knowledge of German might be confused by ‘Pups’. Was für eine Scheiße!