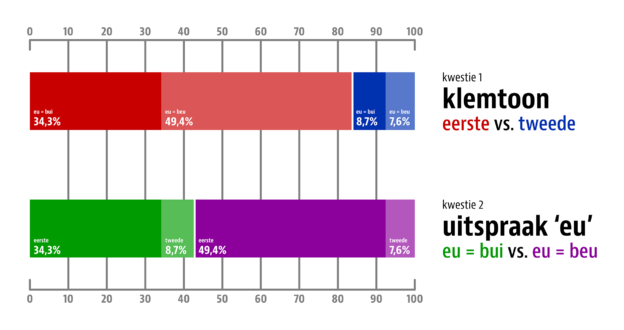
Ich war neulich in einem Einkaufszentrum, fand die Toilette nicht und fragte daher die Mitarbeiterin eines Ladens, wo sich die Toiletten befinden. Sie antwortete: »Beim Woolworth links« – oder phonetisch: [baɪ̯m ˈvɔl.vɔɐ̯t ˈlɪŋs]. Und schon war ich bei der Frage: Wie spricht man eigentlich Woolworth aus?
Die Geschichte der Unternehmen, die unter Woolworth firmier(t)en, ist kompliziert und für die vorliegende Frage so uninteressant, dass ich sie hier nicht zusammenfasse. In jedem Fall wurde das ursprüngliche Unternehmen von Frank Winfield Woolworth (1852–1919), einem amerikanischen Unternehmer, gegründet. Schlägt man seinen Namen in einem Aussprachewörterbuch des Englischen nach (z. B. dem Longman Pronunciation Dictionary), findet man dort für das amerikanische Englisch [ˈwʊl.wɝːθ] und für das britische Englisch [ˈwʊl.wəθ] bzw. [ˈwʊl.wɜːθ]. Hört man sich an, wie englischsprachige Menschen auf YouTube den Namen aussprechen, deckt sich das mit diesen Angaben.
Im Deutschen wird der Name anders ausgesprochen – nicht zuletzt, weil die meisten Laute der englischen Aussprache im deutschen Lautsystem nicht vorkommen. So erscheint [w] im Deutschen nur marginal, nämlich in Entlehnungen aus dem Englischen. Es ist wohl eher als freie Variante von /v/ zu betrachten denn als Phonem. Im Aussprache-DUDEN steht: »Für englisches <w> und <wh> sind eingedeutschtes [v] und ausgangssprachliches [w] üblich, wobei jüngere Entlehnungen oder Wörter mit weiteren englischen Phonemen eher [w] haben.« Das englische /l/ lautet in diesem Wort bzw. in einigen Varietäten generell [ɫ], ist also – anders als im Standarddeutschen – velarisiert. /ɜː/ hat im Deutschen keine direkte Entsprechung. [θ] verhält sich ähnlich wie [w]. Ich zitiere wiederum den Aussprache-DUDEN: »Der nur in wenigen gängigen Entlehnungen vorkommende dentale Frikativ [θ] (Thriller, Thread) wird im Alltag häufig als [s] eingedeutscht (selten als [t]), bei Berufssprechern (v. a. bei englischen Namen) und bei fortgeschrittener Fremdsprachenkenntnis aber regelmäßig als [θ].« Damit ist [ʊ] der einzige Laut in diesem Namen, der im Englischen und Deutschen gleichermaßen vorkommt.
Weiterlesen