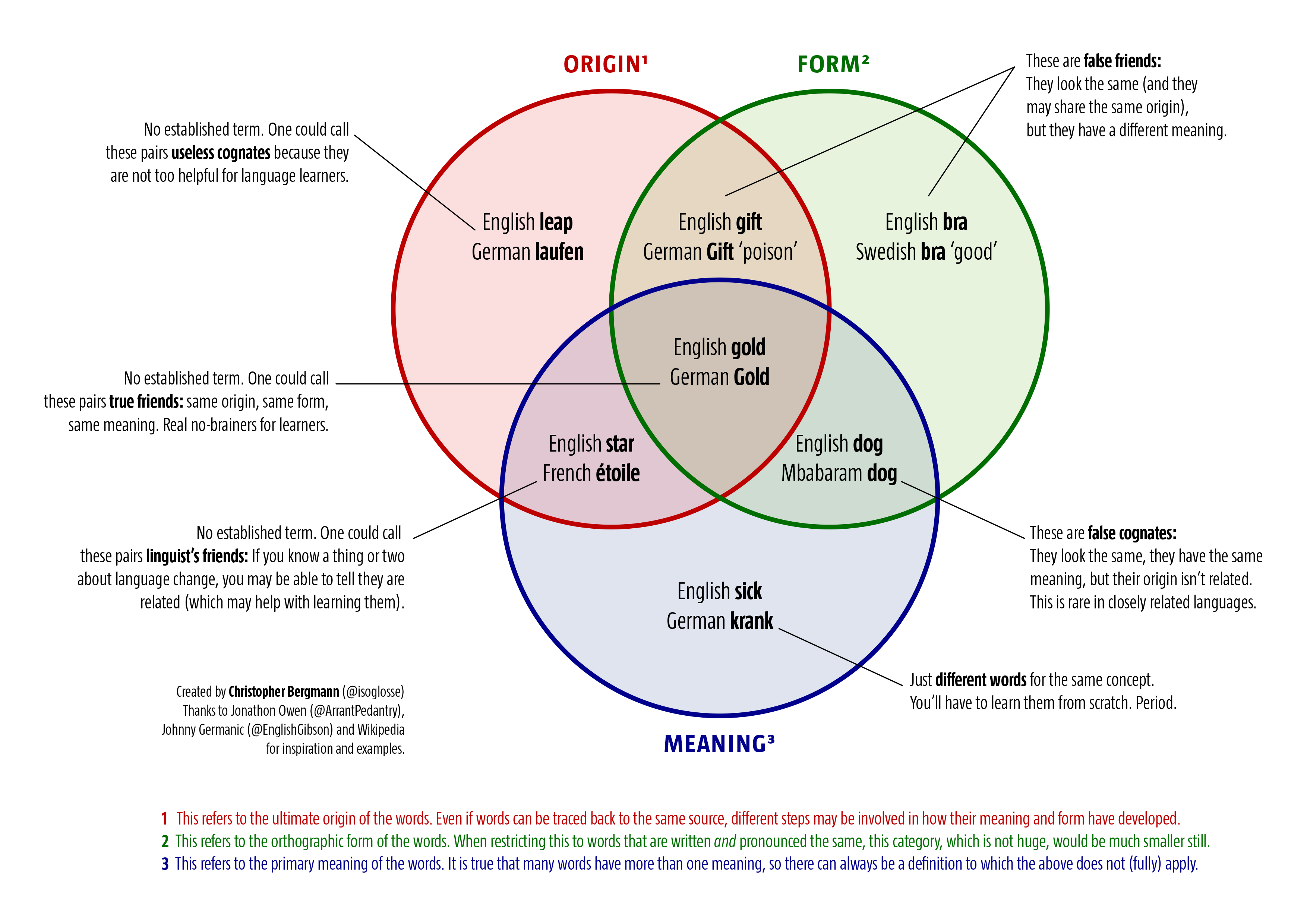
I recently passed through the entrance hall of a public building (which shall not be named). As in the entrance halls of many public buildings, there was a welcome carpet. Welcome carpets tend to be large, but ‘Welcome’ is a short word, so at some time, the makers of welcome carpets came up with the idea of translating the word ‘Welcome’ to other languages and putting these translations on the carpet as well. When you know the location of a carpet, you can predict the selection of translations quite accurately. In Germany, there will be few carpets that feature no English or French translation alongside the German word. Foreign languages that are widely taught (such as Italian or Spanish) and native languages of large immigrant groups (such as Turkish or Arabic) are also often encountered on these carpets.
Going by this, the carpet I saw was a fairly typical one. It had German (obviously), English and French, Italian and Spanish, Turkish (with a minor spelling mistake) and Arabic, and – eh, what is that?

‘Dodpo momaubatg’ did not look like a phrase from any of the languages I speak. The ‘-tg’ ending of the second word seemed to give it a Catalan tinge (but I knew that the Catalan word for ‘welcome’ is ‘benvinguts’). As a whole, the phrase was not recognisably related to any of the terms for ‘welcome’ I was aware of. I did a quick online search, but it did not turn up anything relevant, so I forgot about it and only showed the picture to a friend a few days later. She could not identify the language either, but said that the look of the phrase reminded her of Russian or another language written with the Cyrillic alphabet. To readers like her who only know the Latin alphabet well, Cyrillic letters look vaguely familiar, but you don’t know which sounds they represent and the combination does not make any sense.
The Russian phrase for ‘welcome’ is Добро пожаловать (Dobro požalovat’), but the connection with the phrase on the carpet is not immediately evident. One of my first thoughts was that this might be an example of encoding gone awry – but once you think it through, it does not hold up. First, the number of letters in ‘Dodpo momaubatg’ and the original Russian phrase is not identical (the original phrase has an additional letter in the second word). Second, the first and third letters of both words are different in Russian, but identical on the carpet. Even in a scenario with incorrect encoding or decoding, you would expect different (albeit unexpected) characters in the output for different letters in the input. So what happened instead? To be honest, I am still not entirely sure, but here is my best guess:
Weiterlesen