Vor gut vier Jahren berichtete Anatol Stefanowitsch bei SciLogs über Korpusdaten zum Genus der Wörter ›Blog‹ und ›Weblog‹. Die Daten aus dem Deutschen Referenzkorpus (DeReKo) zeigten damals eine Verschiebung des grammatikalischen Geschlechts vom Neutrum zum Maskulinum. Im Jahr 2010 wurde ›Blog‹ bei rund 70% der genuseindeutigen Belege als Maskulinum verwendet.
Seit der damaligen Auswertung ist das DeReKo erheblich gewachsen. Und wir sind natürlich vier Jahre Sprachverwendung weiter. Aus diesem Grund habe ich eine Aktualisierung und Fortschreibung der Daten zum Genus von ›Blog‹ und ›Weblog‹ erstellt. Die Frage: Ist der Anteil der Belege für Verwendung als Maskulinum weiter gestiegen und, wenn ja, bis zu welchem Niveau? Hier ist die Antwort:
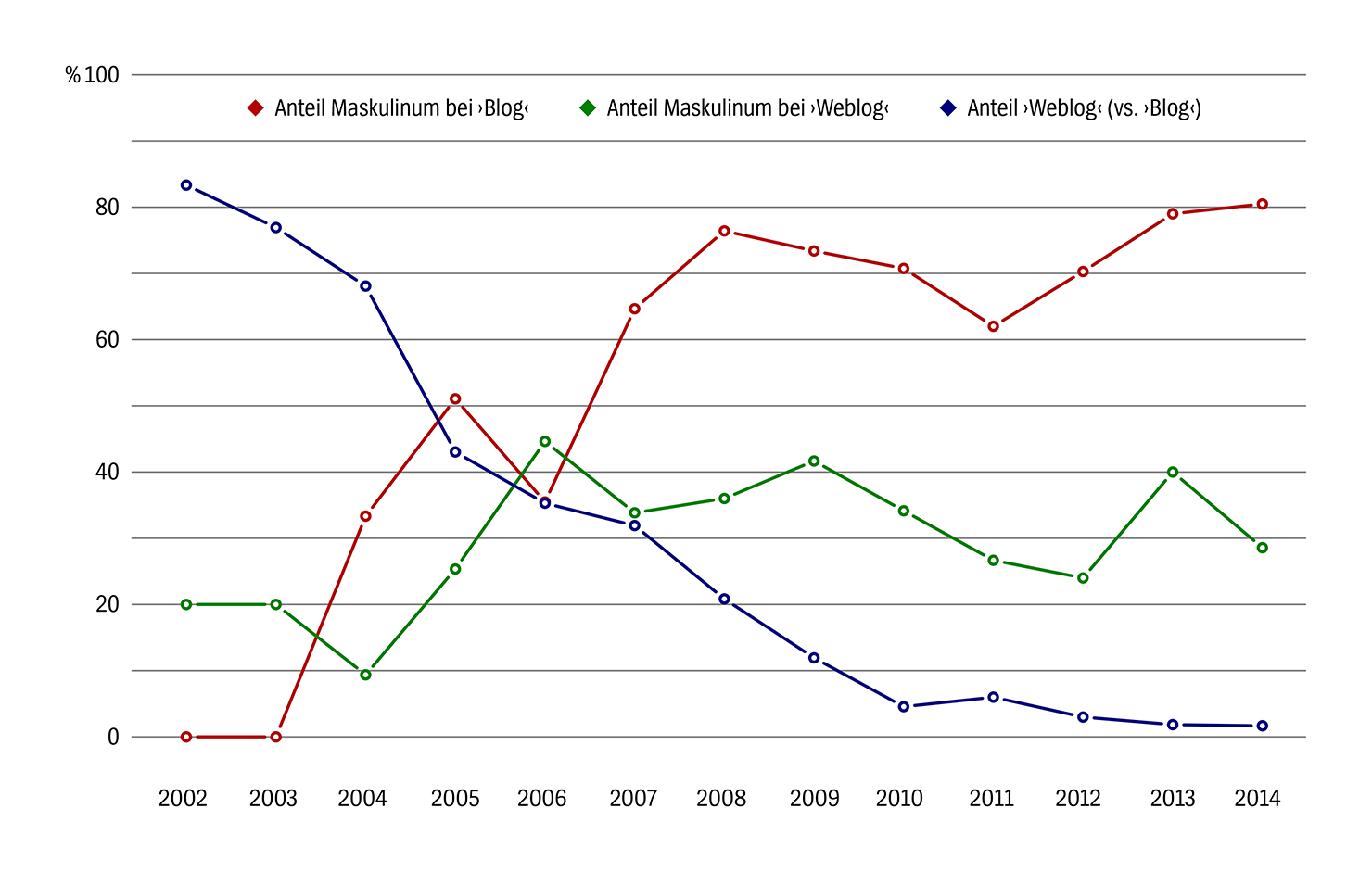
Diese Daten stammen aus den geschriebenen Korpora, die im DeReKo zu den Archiven W, W2, W3 und W4 zusammengefasst sind. Berücksichtigt wurden nur Wortfolgen, bei denen Artikel und Kopfnomen direkt nebeneinander standen. Dieses Diagramm zeigt prozentuale Angaben zu drei Variablen: In rot sieht man den Anteil maskuliner Definitartikel (›der‹ im Nominativ und ›den‹ im Akkusativ) in Nominalphrasen, deren Kopfnomen ›Blog‹ ist. In grün sieht man den Anteil maskuliner Definitartikel in Nominalphrasen, deren Kopfnomen ›Weblog‹ ist. In beiden Fällen entfallen zu 100 fehlende Prozentpunkte auf die Verwendung des neutralen Definitartikels (›das‹ im Nominativ und Akkusativ). In blau sieht man den Anteil der Nominalphrasen mit Kopfnomen ›Weblog‹ an der Gesamtzahl der Nominalphrasen. Hier sind zu 100 fehlende Prozentpunkte der Verwendung von ›Blog‹ als Kopfnomen zuzurechnen.
Interessant an diesem Diagramm finde ich dreierlei:
Zum ersten zeigt sich, dass die Verwendung des Wortes als Maskulinum, die in der alten Auswertung erst 2006 nachzuweisen war, bereits 2002 in der Presse vorkam. Aus diesem Jahr stammt der früheste Beleg für ›der/den Weblog‹ in der aktuellen Version der DeReKo. Die Verwendung von ›Weblog‹ als Maskulinum in dieser Zeit muss man meines Erachtens nicht unbedingt als die Frühphase des Wandels vom Neutrum zum Maskulinum deuten. Sie könnte auch schlicht ein Hinweis darauf sein, dass das Genus dieses seinerzeit noch relativ neuen Lehnwortes – wie das so vieler Lehnwörter – schwankte. ›Der/den Blog‹ ist in der neuen Auswertung bereits in Zeitungen aus dem Jahr 2004 zu finden.
Zum zweiten veranschaulicht das Diagramm den engen Zusammenhang zwischen dem Übergang von ›Weblog‹ zu ›Blog‹ und dem Übergang vom Neutrum zum Maskulinum. Bei ›Weblog‹ überwog die Verwendung als Maskulinum in keinem Jahr (Maximum: 44,6% im Jahr 2006). ›Blog‹ dagegen stieg 2004 bereits mit einem satten Drittel an Verwendungen als Maskulinum ein. Im zweiten Jahr, in dem ›Blog‹ überhaupt als Maskulinum in diesem Korpus nachgewiesen wurde, war das Neutrum schon in der Minderheit. Seit 2007 dominiert das Maskulinum bei ›Blog‹ deutlich. Die Gründe, warum ›Blog‹ eher maskulines Genus annimmt als ›Weblog‹, wurden bereits 2010 besprochen: ›Weblog‹ erinnert noch an ›(das) Logbuch‹, von dem das neutrale Genus auf diese Form des Lehnworts übergegangen sein mag. ›Blog‹ dagegen neigt aus zwei Gründen zum Maskulinum: Einerseits haben Wörter dieser Silbenstruktur (CCVC mit kurzem Vokal) im Deutschen überwiegend maskulines Genus (wie Klaus-Michael Köpcke 1982 in seiner Dissertation gezeigt hat). Andererseits wird die Kurzform genauso ausgesprochen wie ›(der) Block‹ (eines dieser maskulinen CCVC-Wörter), was zur Genusübertragung einlädt.
Zum dritten finde ich es bemerkenswert, dass sich bei beiden Formen – ›Blog‹ und ›Weblog‹ – seit 2007 (oder spätestens 2008) nichts Dramatisches an den Anteilen der Genera geändert hat. Obwohl der Anteil von ›Weblog‹ an der Gesamtzahl der Verwendungen in dieser Zeit von einem knappen Drittel unter zwei Prozent gesunken ist, bleibt der Anteil der Verwendungen als Maskulinum bei rund 30% (mit Ausschlägen nach oben und unten). Und obwohl parallel dazu die Form ›Blog‹ praktisch universell geworden ist, wird sie auch im Jahr 2014 in rund 20% der Fälle als Neutrum verwendet. Das ist insofern ein symbolischer Wert, als auch ›Weblog‹ im ersten Jahr, das unsere Zeitreihe erfasst, in rund 20% der Fälle als Maskulinum verwendet wurde. Vielleicht sind 20% an Sprechern, die ein anderes Genus als die Mehrheit verwenden, einfach ein Residuum an Abweichlern, das nicht so schnell verschwindet – zumindest nicht in den ersten 20, 25 Jahren, die ein Lehnwort in einer Sprache verbringt.